
Overview
In this IBM sponsored project, I assumed the role of a Junior Data Engineer who has recently joined a fictional online e-Commerce company named SoftCart. Presented with real-world use cases, I was required to apply a number of industry standard data engineering solutions.
Objectives
- Demonstrate proficiency in skills required for an entry-level data engineering role
- Design and implement various concepts and components in the data engineering lifecycle such as data repositories
- Showcase working knowledge with relational databases, NoSQL data stores, big data engines, data warehouses, and data pipelines
- Apply skills in Linux shell scripting, SQL, and Python programming languages to Data Engineering problems
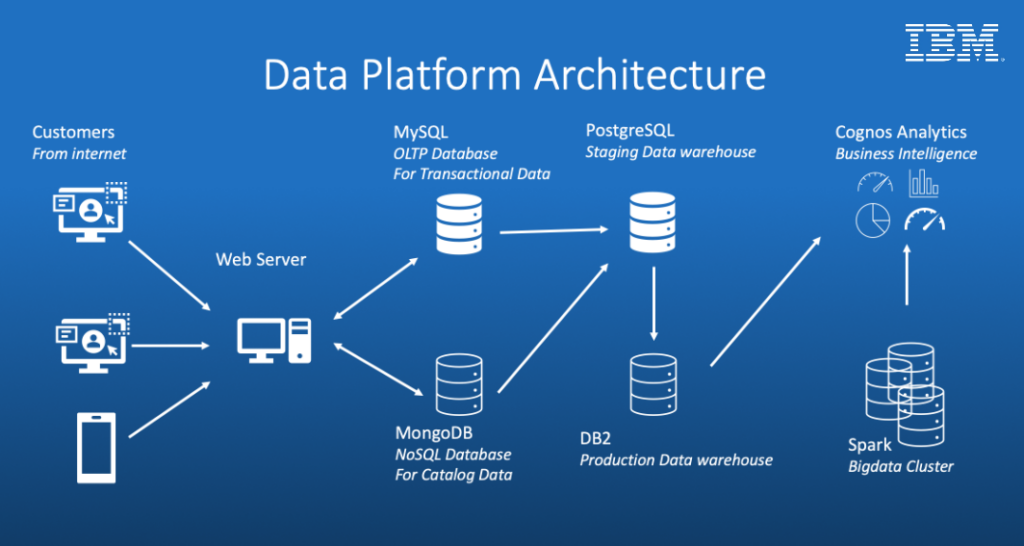
Project Outline
- SoftCart’s online presence is primarily through its website, which customers access using a variety of devices like laptops, mobiles and tablets.
- All the catalog data of the products is stored in the MongoDB NoSQL server.
- All the transactional data like inventory and sales are stored in the MySQL database server.
- SoftCart’s webserver is driven entirely by these two databases.
- Data is periodically extracted from these two databases and put into the staging data warehouse running on PostgreSQL.
- Production data warehouse is on the cloud instance of IBM DB2 server.
- BI teams connect to the IBM DB2 for operational dashboard creation. IBM Cognos Analytics is used to create dashboards.
- SoftCart uses Hadoop cluster as it big data platform where all the data collected for analytics purposes.
- Spark is used to analyse the data on the Hadoop cluster.
- To move data between OLTP, NoSQL and the dataware house ETL pipelines are used and these run on Apache Airflow.
Tools/Software
- OLTP Database – MySQL
- NoSql Database – MongoDB
- Production Data Warehouse – DB2 on Cloud
- Staging Data Warehouse – PostgreSQL
- Big Data Platform – Hadoop
- Big Data Analytics Platform – Spark
- Business Intelligence Dashboard – IBM Cognos Analytics
- Data Pipelines – Apache Airflow